想要探索像 ChatGPT 和 Copilot 這樣的 AI 驅動聊天機器人的功能,而不依賴第三方服務嗎?使用 Ollama 和一些設定,您可以運行自己的 ChatGPT 實例並自訂它以符合您的特定需求。無論您是想將對話式 AI 整合到應用程式或專案中的開發者、尋求分析 AI 模型效能的研究人員,還是只是想嘗試這項尖端技術的愛好者 - 控制自己的聊天機器人可以為創新和發現開啟令人興奮的可能性。
無論如何,我想運行自己的 ChatGPT 和 Copilot。
設定 Ollama
首先,您必須設定 Ollama。到目前為止,我還沒有聽到任何關於在任何平台(包括 Windows WSL)上設定 Ollama 困難的抱怨。Ollama 準備好後,拉取一個模型,如 Llama 3:
$ # 拉取 5GB 模型可能需要一些時間...
$ ollama pull llama3:instruct
$ # 列出您擁有的模型
$ ollama list
NAME ID SIZE MODIFIED
llama3:instruct 71a106a91016 4.7 GB 11 days ago通過命令列測試模型,儘管措辭可能不同:
$ ollama run llama3:instruct
>>> Send a message (/? for help)
>>> are you ready?
I'm always ready to play a game, answer questions, or just chat. What's on your mind? Let me know what you'd like
to do and I'll do my best to help.檢查 Ollama 的連接埠是否正在監聽:
$ netstat -a -n | grep 11434
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN
$ # 看起來不錯,連接埠 11434 已準備好
$ # 如果 Ollama 沒有監聽,請運行以下命令
ollama serve請查看 https://ollama.com/library 以獲取可用模型清單。
Gradio
雖然您可以設定系統提示、參數、嵌入內容和一些前/後處理,但您可能想要一種更簡單的方式通過網頁介面進行互動。您需要 Gradio。假設您已準備好 Python:
$ # 建立 Python 虛擬環境。
$ # gradio-env 是資料夾名稱,您可以將其更改為任何名稱
$ python -m venv gradio-env
$ # 進入虛擬環境
$ gradio-env/Script/activate
$ # 如果您使用 Windows
$ gradio-env\script\activate.bat
$ # 安裝 Gradio
$ pip install gradio接下來,建立一個 Python 腳本,檔案名稱如 app.py。如果您使用其他模型,請更新模型:
app.pyimport requests import json import gradio as gr model = "llama3:instruct" url = "http://localhost:11434/api/" def generate_response(prompt, history): data = {"model": model, "stream": False, "prompt": prompt} response = requests.post( url + "generate", headers={"Content-Type": "application/json", "Connection": "close"}, data=json.dumps(data), ) if response.status_code == 200: return json.loads(response.text)["response"] else: print("Error: generate response:", response.status_code, response.text) demo = gr.ChatInterface( fn=generate_response ) if __name__ == "__main__": demo.launch()
運行以下命令,您可以使用 URL 訪問介面:
$ gradio app.py
Watching:
...
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.開啟 http://127.0.0.1:7860
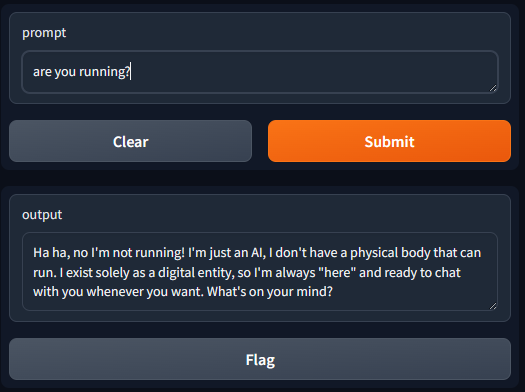
列出模型
假設您已拉取多個模型,並且想從下拉清單中選擇。首先,您從 API 獲取清單:
app.pydef list_models(): response = requests.get( url + "tags", headers={"Content-Type": "application/json", "Connection": "close"}, ) if response.status_code == 200: models = json.loads(response.text)["models"] return [d['model'] for d in models] else: print("Error:", response.status_code, response.text) models = list_models()
然後,您可以將下拉清單添加到 ChatInterface 中:
app.pywith gr.Blocks() as demo: dropdown = gr.Dropdown(label='Model', choices=models) # 選擇第一個項目作為預設模型 dropdown.value = models[0] gr.ChatInterface(fn=generate_response, additional_inputs=dropdown)
現在 generate_response 函數從 additional_inputs 下拉清單中接受一個額外參數。更新函數:
app.pydef generate_response(prompt, history, model): data = {"model": model, "stream": False, "prompt": prompt} response = requests.post( url + "generate", headers={"Content-Type": "application/json", "Connection": "close"}, data=json.dumps(data), ) if response.status_code == 200: return json.loads(response.text)["response"] else: print("Error: generate response:", response.status_code, response.text)
展開額外輸入後,您可以看到下拉清單:
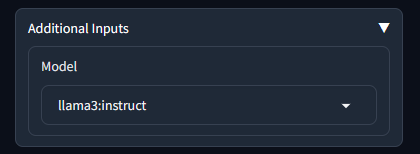
使用聊天歷史記錄
先前的實作使用了 Ollama 的 generate API。該 API 接受一個簡單的參數 prompt,允許將聊天歷史記錄與提示一起發送。然而,最好使用 Ollama 的 chat API,它接受 messages 參數。這個 messages 參數可以指定角色,使模型能夠更好地解釋和相應地回應。下面演示如何將 history 放入 API 格式,最後一條訊息是最新的使用者輸入。
app.pydef generate_response(prompt, history, model): messages = [] for u, a in history: messages.append({"role": "user", "content": u}) messages.append({"role": "assistant", "content": a}) messages.append({"role": "user", "content": prompt}) data = {"model": model, "stream": False, "messages": messages} response = requests.post( url + "chat", headers={"Content-Type": "application/json", "Connection": "close"}, data=json.dumps(data), ) if response.status_code == 200: bot_message = json.loads(response.text)["message"]["content"] return bot_message else: print("Error: generate response:", response.status_code, response.text)
Visual Studio Code 與擴充功能
像 Continue 這樣的擴充功能非常容易設定。
您可以設定 Ollama 或更新擴充功能的 config.json:
"models": [
{
"model": "llama3:instruct",
"title": "llama3:instruct",
"completionOptions": {},
"apiBase": "http://localhost:11434",
"provider": "ollama"
}
],您可以為本地 copilot 設定模型角色:
"modelRoles": {
"default": "llama3:instruct",
"summarize": "llama3:instruct"
},在本地機器外提供 Gradio 或 Ollama API
預設情況下,Gradio 和 Ollama 僅在 localhost 上監聽,這意味著出於安全原因,網路上的其他人無法訪問它們。您可以通過像 Nginx 這樣的代理和 API 閘道提供網頁或 API,以實現傳輸中的資料加密和身份驗證。然而,為了簡單起見,您可以設定以下內容以允許所有 IP 訪問您的本地 Ollama:
$ # 配置 Ollama 監聽所有 IP
$ sudo echo "[Service]\nEnvironment=\"OLLAMA_HOST=0.0.0.0\"" > /etc/systemd/system/ollama.service.d/http-host.conf
$
$ sudo systemctl daemon-reload
$ sudo systemctl restart ollama
$
$ # 如果需要,開啟防火牆
$ sudo ufw allow from any to any port 11434 proto tcp對於 Gradio,您可以將 server_name 設定為 0.0.0.0:
demo.launch(server_name="0.0.0.0")如果您通過 WSL 運行 Gradio 和 Ollama,您需要使用 PowerShell 命令將連接埠從 WSL 轉發到本地機器:
If (-NOT ([Security.Principal.WindowsPrincipal][Security.Principal.WindowsIdentity]::GetCurrent()).IsInRole([Security.Principal.WindowsBuiltInRole] "Administrator")) {
$arguments = "& '" + $myinvocation.mycommand.definition + "'"
Start-Process powershell -Verb runAs -ArgumentList $arguments
Break
}
$remoteport = bash.exe -c "ifconfig eth0 | grep 'inet '"
$found = $remoteport -match '\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}';
if ($found) {
$remoteport = $matches[0];
}
else {
Write-Output "IP address could not be found";
exit;
}
$ports = @(7860,11434);
for ($i = 0; $i -lt $ports.length; $i++) {
$port = $ports[$i];
Invoke-Expression "netsh interface portproxy delete v4tov4 listenport=$port";
Invoke-Expression "netsh advfirewall firewall delete rule name=$port";
Invoke-Expression "netsh interface portproxy add v4tov4 listenport=$port connectport=$port connectaddress=$remoteport";
Invoke-Expression "netsh advfirewall firewall add rule name=$port dir=in action=allow protocol=TCP localport=$port";
}
Invoke-Expression "netsh interface portproxy show v4tov4";更新腳本中的連接埠 7860,11434 以符合您自己的需求。7860 用於 Gradio,11434 用於 ollama
玩得開心!