
ChatGPTやCopilotのようなAI搭載チャットボットの機能を、サードパーティのサービスに依存せずに探求したいと思ったことはありませんか?Ollamaといくつかのセットアップで、独自のChatGPTインスタンスを実行し、特定のニーズに合わせてカスタマイズできます。アプリやプロジェクトに会話型AIを統合しようとしている開発者、AIモデルのパフォーマンスを分析しようとしている研究者、または単にこの最先端技術を実験したい愛好家であっても、独自のチャットボットを制御することで、イノベーションと発見のエキサイティングな可能性が開かれます。
とにかく、私は独自のChatGPTとCopilotを実行したいです。
Ollamaのセットアップ
まず、Ollamaをセットアップする必要があります。これまでのところ、Windows WSLを含むどのプラットフォームでもOllamaのセットアップが難しいという苦情は聞いたことがありません。Ollamaの準備ができたら、Llama 3のようなモデルをプルします:
$ # 5GBのモデルをプルするには時間がかかる場合があります...
$ ollama pull llama3:instruct
$ # 持っているモデルをリストアップ
$ ollama list
NAME ID SIZE MODIFIED
llama3:instruct 71a106a91016 4.7 GB 11 days agoコマンドラインを通じてモデルをテストします。ただし、文言は異なる場合があります:
$ ollama run llama3:instruct
>>> Send a message (/? for help)
>>> are you ready?
I'm always ready to play a game, answer questions, or just chat. What's on your mind? Let me know what you'd like
to do and I'll do my best to help.Ollamaのポートがリスニングしているか確認します:
$ netstat -a -n | grep 11434
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN
$ # 良さそうです、ポート11434は準備ができています
$ # Ollamaがリスニングしていない場合は以下のコマンドを実行
ollama serve利用可能なモデルのリストについては https://ollama.com/library を確認してください。
Gradio
システムプロンプト、パラメータ、埋め込みコンテンツ、および一部の前処理/後処理をセットアップできますが、Webインターフェースを通じてやり取りするより簡単な方法が必要かもしれません。Gradioが必要です。Pythonの準備ができていると仮定します:
$ # Python仮想環境を作成
$ # gradio-envはフォルダ名で、任意の名前に変更できます
$ python -m venv gradio-env
$ # 仮想環境に入る
$ gradio-env/Script/activate
$ # Windowsを使用している場合
$ gradio-env\script\activate.bat
$ # Gradioをインストール
$ pip install gradio次に、app.pyのようなファイル名でPythonスクリプトを作成します。別のモデルを使用している場合はモデルを更新してください:
app.pyimport requests import json import gradio as gr model = "llama3:instruct" url = "http://localhost:11434/api/" def generate_response(prompt, history): data = {"model": model, "stream": False, "prompt": prompt} response = requests.post( url + "generate", headers={"Content-Type": "application/json", "Connection": "close"}, data=json.dumps(data), ) if response.status_code == 200: return json.loads(response.text)["response"] else: print("Error: generate response:", response.status_code, response.text) demo = gr.ChatInterface( fn=generate_response ) if __name__ == "__main__": demo.launch()
以下のコマンドを実行すると、URLでインターフェースにアクセスできます:
$ gradio app.py
Watching:
...
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.http://127.0.0.1:7860を開きます
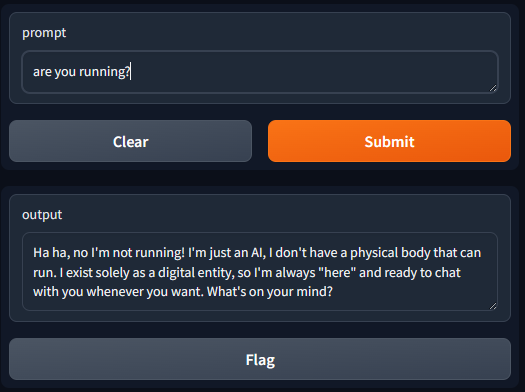
モデルのリスト表示
複数のモデルをプルしていて、ドロップダウンリストから選択したいと仮定します。まず、APIからリストを取得します:
app.pydef list_models(): response = requests.get( url + "tags", headers={"Content-Type": "application/json", "Connection": "close"}, ) if response.status_code == 200: models = json.loads(response.text)["models"] return [d['model'] for d in models] else: print("Error:", response.status_code, response.text) models = list_models()
次に、ChatInterfaceにドロップダウンを追加できます:
app.pywith gr.Blocks() as demo: dropdown = gr.Dropdown(label='Model', choices=models) # デフォルトモデルとして最初のアイテムを選択 dropdown.value = models[0] gr.ChatInterface(fn=generate_response, additional_inputs=dropdown)
これで、generate_response関数はadditional_inputsドロップダウンから追加のパラメータを受け取ります。関数を更新します:
app.pydef generate_response(prompt, history, model): data = {"model": model, "stream": False, "prompt": prompt} response = requests.post( url + "generate", headers={"Content-Type": "application/json", "Connection": "close"}, data=json.dumps(data), ) if response.status_code == 200: return json.loads(response.text)["response"] else: print("Error: generate response:", response.status_code, response.text)
追加入力を展開すると、ドロップダウンが表示されます:
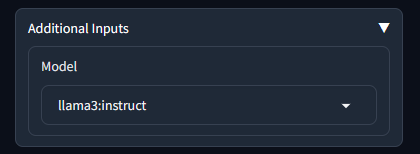
チャット履歴の使用
以前の実装では、OllamaのgenerateAPIを利用していました。このAPIは、プロンプトと一緒にチャット履歴を送信できる単純なパラメータpromptを受け入れました。ただし、messagesパラメータを受け入れるOllamaのchatAPIを使用する方が良いです。このmessagesパラメータは役割を指定でき、モデルがより適切に解釈して応答できるようになります。以下は、historyをAPI形式に入れる方法を示しており、最後のメッセージが最新のユーザー入力です。
app.pydef generate_response(prompt, history, model): messages = [] for u, a in history: messages.append({"role": "user", "content": u}) messages.append({"role": "assistant", "content": a}) messages.append({"role": "user", "content": prompt}) data = {"model": model, "stream": False, "messages": messages} response = requests.post( url + "chat", headers={"Content-Type": "application/json", "Connection": "close"}, data=json.dumps(data), ) if response.status_code == 200: bot_message = json.loads(response.text)["message"]["content"] return bot_message else: print("Error: generate response:", response.status_code, response.text)
拡張機能を使用したVisual Studio Code
Continueのような拡張機能は非常に簡単にセットアップできます。
Ollamaをセットアップするか、拡張機能のconfig.jsonを更新できます:
"models": [
{
"model": "llama3:instruct",
"title": "llama3:instruct",
"completionOptions": {},
"apiBase": "http://localhost:11434",
"provider": "ollama"
}
],ローカルコパイロットにモデルの役割を設定できます:
"modelRoles": {
"default": "llama3:instruct",
"summarize": "llama3:instruct"
},ローカルマシンの外部でGradioまたはOllama APIを提供する
デフォルトでは、GradioとOllamaはlocalhostでのみリスニングします。つまり、セキュリティ上の理由から、ネットワークから他の人がそれらに到達できません。NginxやAPIゲートウェイのようなプロキシを通じてWebまたはAPIを提供して、転送中のデータ暗号化と認証を行うことができます。ただし、簡単にするために、すべてのIPがローカルOllamaにアクセスできるように以下を設定できます:
$ # すべてのIPをリスニングするようにOllamaを設定
$ sudo echo "[Service]\nEnvironment=\"OLLAMA_HOST=0.0.0.0\"" > /etc/systemd/system/ollama.service.d/http-host.conf
$
$ sudo systemctl daemon-reload
$ sudo systemctl restart ollama
$
$ # 必要に応じてファイアウォールを開く
$ sudo ufw allow from any to any port 11434 proto tcpGradioの場合、server_nameを0.0.0.0に設定できます:
demo.launch(server_name="0.0.0.0")WSLを通じてGradioとOllamaを実行している場合、PowerShellコマンドを使用してWSLからローカルマシンにポートを転送する必要があります:
If (-NOT ([Security.Principal.WindowsPrincipal][Security.Principal.WindowsIdentity]::GetCurrent()).IsInRole([Security.Principal.WindowsBuiltInRole] "Administrator")) {
$arguments = "& '" + $myinvocation.mycommand.definition + "'"
Start-Process powershell -Verb runAs -ArgumentList $arguments
Break
}
$remoteport = bash.exe -c "ifconfig eth0 | grep 'inet '"
$found = $remoteport -match '\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}';
if ($found) {
$remoteport = $matches[0];
}
else {
Write-Output "IP address could not be found";
exit;
}
$ports = @(7860,11434);
for ($i = 0; $i -lt $ports.length; $i++) {
$port = $ports[$i];
Invoke-Expression "netsh interface portproxy delete v4tov4 listenport=$port";
Invoke-Expression "netsh advfirewall firewall delete rule name=$port";
Invoke-Expression "netsh interface portproxy add v4tov4 listenport=$port connectport=$port connectaddress=$remoteport";
Invoke-Expression "netsh advfirewall firewall add rule name=$port dir=in action=allow protocol=TCP localport=$port";
}
Invoke-Expression "netsh interface portproxy show v4tov4";スクリプト内のポート7860,11434を自分のものに合わせて更新してください。7860はGradio用、11434はollama用です
楽しんでください!